Ejecución de modelos de IA localmente con Ollama
Ejecución de modelos de IA localmente con Ollama
Sección titulada «Ejecución de modelos de IA localmente con Ollama»Ollama es una herramienta que permite ejecutar modelos de lenguaje grandes (LLMs) localmente en tu máquina. Esto es especialmente útil para aquellos que desean mantener la privacidad de sus datos o reducir la dependencia de servicios en la nube. A continuación, se detalla cómo integrar Ollama con ArchiHUB para aprovechar modelos de IA localmente.
Requisitos previos
Sección titulada «Requisitos previos»Antes de comenzar, asegúrate de tener habilitado el contenedor de Ollama en el docker-compose.yml de ArchiHUB. Debes tener una configuración similar a la siguiente:
archihub_ollama: image: ollama/ollama:latest ports: - "${OLLAMA_PORT}:${OLLAMA_PORT}" volumes: - ${OLLAMA_PATH}:/root/.ollama environment: <<: *backend_env_variables CUDA_VISIBLE_DEVICES: 0 networks: - archihub_mongo_network - archihub_elastic_network command: serve deploy: resources: reservations: devices: - driver: nvidia count: 1 capabilities: [gpu] restart: unless-stoppedConfiguración de variables de entorno relacionadas con Ollama (en el archivo .env)
Sección titulada «Configuración de variables de entorno relacionadas con Ollama (en el archivo .env)»Para el funcionamiento adecuado de Ollama con ArchiHUB, es necesario configurar las siguientes variables de entorno en el archivo .env:
# Ollama settingsOLLAMA_HOST=archihub_ollama # Nombre del servicio del contenedor OllamaOLLAMA_PORT=11434OLLAMA_PATH=/path/to/ollama/dataInstalación de modelos en Ollama
Sección titulada «Instalación de modelos en Ollama»Una vez que Ollama esté en funcionamiento, puedes instalar modelos de IA utilizando el comando ollama pull. Por ejemplo, para instalar el modelo llama2, ejecuta el siguiente comando en la terminal:
docker exec -it archihub_ollama ollama pull llama2 # Reemplaza "llama2" con el nombre del modelo que deseas instalar. Valida el nombre del contenedor.Creación del asistente en ArchiHUB
Sección titulada «Creación del asistente en ArchiHUB»Después de instalar los modelos en Ollama, ArchiHUB podrá utilizarlos para diversas tareas de inteligencia artificial. Para esto, desde el menú de asistentes de IA en ArchiHUB, selecciona Ollama como el proveedor de IA y asigna un nombre al asistente:
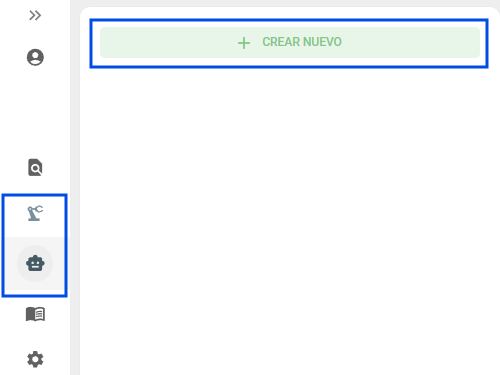
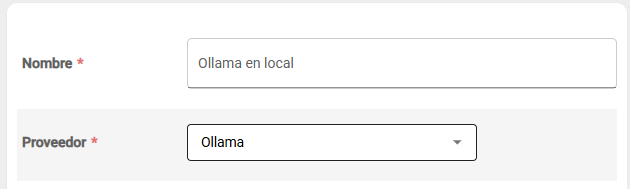
Con estos pasos, habrás configurado exitosamente Ollama para ejecutar modelos de IA localmente en ArchiHUB. Ahora puedes aprovechar las capacidades de inteligencia artificial sin depender de servicios externos.
Uso de modelos en ArchiHUB
Sección titulada «Uso de modelos en ArchiHUB»Una vez que el asistente de Ollama esté configurado en ArchiHUB, podrás utilizar los modelos instalados para diversas tareas, como generación de texto, análisis de documentos, entre otros. A continuación, se presenta un listado de recursos que el asistente puede utilizar:
- Documentos cargados en ArchiHUB.
- Imágenes cargadas en ArchiHUB (si el modelo lo soporta).
- Transcripciones de audio a texto.
- Información adicional proporcionada por el usuario.
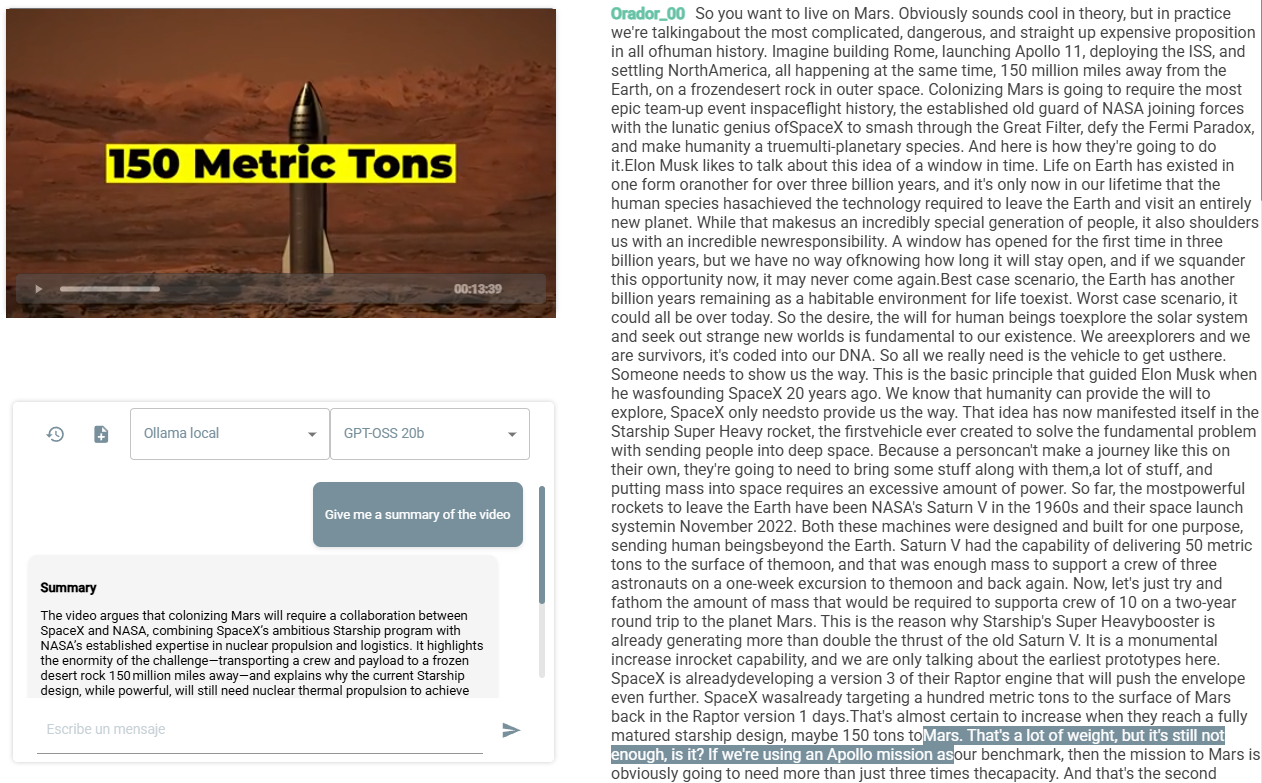
Por ejemplo, si tienes un video que se transcribió usando el plugin de transcripción, el asistente podrá analizar el texto resultante para responder preguntas o generar resúmenes basados en el contenido del video:
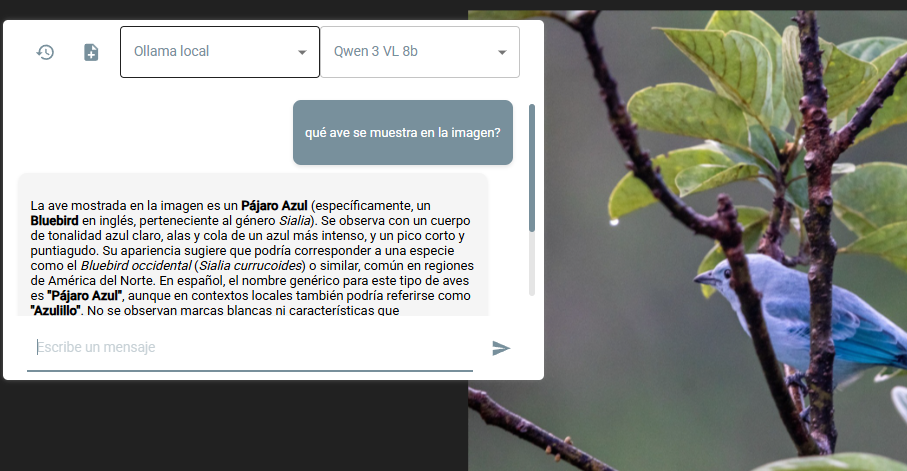
O si quieres identificar un ave a partir de una imagen cargada en ArchiHUB, el asistente podrá ayudarte a identificarla utilizando el modelo de Ollama que soporte análisis de imágenes: